强化学习入门知识

强化学习入门知识
Holi本文参考莫烦python-强化学习。
基本概念
一种对强化学习的直观理解就是通过不断地尝试,从实践中学习,最终找到某种规律,得到一个训练后的agent。从实践中学习需要一个老师,这个老师会根据agent的行为进行打分,agent的训练过程实际上就是记住了各种行为对应的打分。
监督学习中使用的数据是同时包含数据和正确标签的,而强化学习可以认为老师给行为打的分数就是某种标签。
强化学习分类
model-free和model-based
在model-free的方法中,都是直接从环境中得到反馈然后学习,比如Q Learning,Sarsa,Policy Gradients。而model-based则增加了一个程序,为真实世界增加了建模模型来进行模拟,这种方法可以模拟一些真实场景中不存在的情况,并且这种训练出来的RL模型具有一定想象力,可以预判接下来要发生的所有情况来进行行为选择。
基于概率和基于价值
基于概率的模型可以通过感官分析下一步要采取的各种动作的概率,然后根据概率采取行动,比如Policy Gradients。而基于价值的模型则是会直接选择价值最高的动作,比如Q Learning,Sarsa。还有一种结合二者的方法,叫做Actor-Critic,actor 会基于概率做出动作, 而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程。
回合更新和单步更新
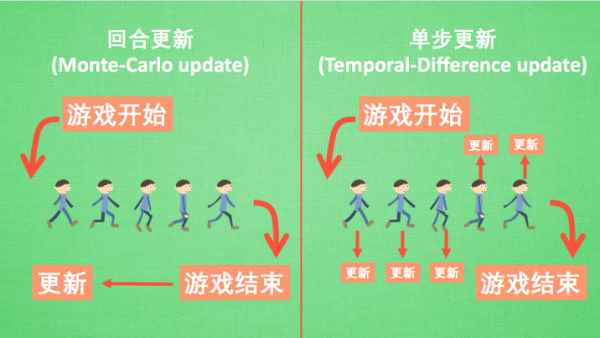
回合更新是在游戏结束后再总结这一回合中所有转折点,进行行为准则更新。而单步更新则是在游戏进行中每一步都在更新,不需要等到游戏结束。
Monte-carlo learning 和基础版的 policy gradients 等 都是回合更新制, Q learning, Sarsa,升级版的 policy gradients 等都是单步更新制。因为单步更新更有效率,所以现在大多方法都是基于单步更新。比如有的强化学习问题并不属于回合问题。
在线学习和离线学习
在线学习就是指必须本人在场,边玩边学。离线学习则是可以选择自己玩,也可以选择看着别人玩,通过别人玩的记录来学习自己的行为准则。
最典型的在线学习就是 Sarsa 了,还有一种优化 Sarsa 的算法,叫做 Sarsa lambda,最典型的离线学习就是 Q learning,后来人也根据离线学习的属性,开发了更强大的算法,比如让计算机学会玩电动的 Deep-Q-Network。
几种算法简介
Q-Learning
$s$为状态,$a$为行动,$Q(s,a)$为状态$s$下选择行动$a$的收益,$R$为处于某个状态下的收益。在某一个当前状态$s_t$下,单次执行可以套用如下公式:
- 选择收益$Q(s_t,a_t)$最高的行动$a_t$,这样行动后的下一步状态是$s_{t+1}$
- 更新收益$Q^{new}(s_t,a_t)\leftarrow(1-\alpha)Q(s_t,a_t)+\alpha(R_{t+1}+\gamma\max_a Q(s_{t+1},a))$
要注意的是Q Learning说到并不一定做到,所以也被叫做off-policy,离线学习。
Sarsa

Sarsa和Q Learning的主要步骤很像,但是有一个核心的步骤是不同的,那就是它说到做到,在更新Q值的过程中并不一定会选择最大Q对应的步行动$a$作为更新,而是采用某种与Q相关的策略。
Q Learning的机器人永远会选择最近的一条通向成功的路,即使可能很危险,而Sarsa则比较保守,希望能够离危险远一些,拿到宝箱是次要的。
【Epsilon greedy 是用在决策上的一种策略,比如 epsilon = 0.9 时,就说明有90% 的情况我会按照 Q 表的最优值选择行为,10% 的时间使用随机选行为】
Sarsa(lambda)

Sarsa是一种单步更新方法,这可以被成为Sarsa(0),因为它在走完当前这一步之后直接更新行为准则,而假如走完这步再走一步再更新,那么就可以称为Sarsa(1)。以此类推,这就是Sarsa(lambda)。
“虽然我们每一步都在更新,但是在没有获取宝藏的时候,我们现在站着的这一步也没有得到任何更新,也就是直到获取宝藏时,我们才为获取到宝藏的上一步更新为:这一步很好,和获取宝藏是有关联的,而之前为了获取宝藏所走的所有步都被认为和获取宝藏没关系。回合更新虽然我要等到这回合结束,才开始对本回合所经历的所有步都添加更新,但是这所有的步都是和宝藏有关系的,都是为了得到宝藏需要学习的步,所以每一个脚印在下回合被选则的几率又高了一些。在这种角度来看,回合更新似乎会有效率一些。”
”其实 lambda 就是一个衰变值,他可以让你知道离奖励越远的步可能并不是让你最快拿到奖励的步,所以我们想象我们站在宝藏的位置,回头看看我们走过的寻宝之路,离宝藏越近的脚印越看得清,远处的脚印太渺小,我们都很难看清,那我们就索性记下离宝藏越近的脚印越重要,越需要被好好的更新。和之前我们提到过的 奖励衰减值 gamma 一样,lambda 是脚步衰减值,都是一个在 0 和 1 之间的数。“
DQN
对于某些问题,是难以建立一个包含所有状态和行动的Q值表的,因为状态过于多了,比如围棋,因此不妨直接使用神经网络来拟合这个Q值表,其可以接受状态和行动并输出对应的Q值。









